知识图谱作为结构化的语义知识库,已在搜索引擎、智能问答、推荐系统等众多领域展现出巨大价值。构建与维护一个大规模知识图谱,其核心挑战之一在于海量、多源、异构数据的处理与高效存储。本文将深入解析大规模知识图谱数据存储的实战要点,并探讨支撑其稳定运行的数据处理与存储支持服务。
一、 大规模知识图谱数据的特征与挑战
大规模知识图谱数据通常具备以下特征,这些特征直接决定了存储方案的设计:
- 海量性(Volume):实体、关系、属性的数量可达数十亿甚至千亿级,数据量庞大。
- 异构性(Heterogeneity):数据来源多样,包括结构化数据库、半结构化网页、非结构化文本等,格式与质量不一。
- 关联性(Connectedness):核心价值在于实体间丰富的语义关系,形成复杂的网络结构,对关联查询性能要求极高。
- 动态性(Dynamics):知识需要持续更新,支持增删改操作,同时需维护数据的一致性与历史版本。
主要挑战包括:如何设计存储模型以高效表达图结构;如何支持低延迟的复杂图遍历与多跳查询;如何保证海量数据下的写入与更新性能;以及如何实现系统的水平扩展与高可用。
二、 核心存储模型与选型实战
存储方案的选择是实战中的首要决策,主流路径包括:
1. 专用图数据库(Native Graph Database)
- 代表:Neo4j, JanusGraph, Nebula Graph, TigerGraph。
- 优势:以“节点-边-属性”为原生存储模型,为图遍历和关系查询做了深度优化,尤其擅长执行多跳查询、最短路径、社区发现等操作。存储与计算引擎一体,开发效率高。
- 实战场景:适用于关系查询为核心、图拓扑复杂的业务,如社交网络分析、金融反欺诈、供应链溯源。
2. 三元组存储(Triple Store)与RDF数据库
- 代表:Virtuoso, Amazon Neptune (RDF模式), AllegroGraph。
- 优势:基于RDF(资源描述框架)标准,使用SPARQL查询语言,在语义Web和逻辑推理场景中具有天然优势。数据模型高度灵活,易于集成来自不同本体的数据。
- 实战场景:适用于需要强语义标准、复杂本体推理、或与Linked Data生态集成的项目。
3. 通用存储引擎的图扩展
- 基于关系型数据库:通过邻接表、路径枚举等模式存储图,利用SQL进行查询。优势在于技术成熟、事务支持强,但复杂查询性能可能成为瓶颈。
- 基于宽列/键值数据库:如HBase, Cassandra,可将节点和边分别存储,通过精心设计的RowKey支持一定程度的图查询。优势在于极强的水平扩展性和海量数据吞吐能力。
- 实战场景:适用于已将特定数据库作为技术栈核心,且图查询模式相对固定或简单的超大规模场景,可作为底层存储,上层构建图计算服务。
选型建议:没有“银弹”。需综合评估查询模式(OLTP型点边查询 vs. OLAP型全图分析)、数据规模、性能要求、团队技能和成本。混合存储架构(如将热数据与复杂查询交给图数据库,冷数据与批量分析放在HDFS/HBase)在实践中也颇为常见。
三、 数据处理与存储支持服务详解
仅有存储引擎不足以支撑生产级系统,需要一套完整的支持服务体系。
1. 数据接入与预处理服务
- 多源采集:构建灵活的数据管道,从API、数据库、日志、流数据中持续抽取信息。
- 实体链接与消歧:服务将抽取出的候选实体与知识图谱中已有实体进行链接,解决同名异义、异名同义问题,这是保证数据质量的关键。
- 标准化与质量校验:对属性值进行格式统一、单位转换、异常值检测与清洗。
2. 存储层优化与运维服务
- 数据分区与分片策略:根据业务查询模式(如按实体类型、地理区域、时间范围)设计分区键,避免热点,实现负载均衡。图数据库通常提供自动分片功能,但需根据数据特性调优。
- 索引策略:针对高频查询条件(如实体ID、属性值、边类型)建立复合索引,大幅提升点查和特定模式匹配速度。但需权衡索引带来的写入开销和存储成本。
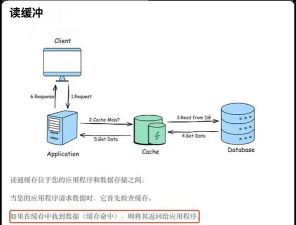
- 缓存体系:构建多级缓存(如应用层缓存热点实体和关系,存储引擎自身缓存热数据),显著降低读延迟。
- 备份、容灾与监控:提供定期的全量与增量备份方案,跨机房/地域的容灾部署。实施全面的监控,覆盖集群健康度、查询性能(P99延迟)、资源利用率等核心指标。
3. 查询与计算服务
- 查询接口与优化:提供友好的API(如GraphQL、RESTful)封装底层查询语言(Cypher, Gremlin, SPARQL)。内置查询优化器,对执行计划进行选择与重写。
- 批量图计算支持:与Spark、Flink等大数据计算框架集成,支持离线的大规模图分析任务(如PageRank、LPA社区发现),将结果写回知识图谱或用于业务决策。
4. 数据生命周期与治理服务
- 版本管理与溯源:记录知识的来源、抽取时间、置信度以及变更历史,支持数据溯源和合规审计。
- 冷热数据分层:根据访问频率将数据划分为热、温、冷层,分别采用高性能存储、标准存储和廉价对象存储,优化总体成本。
- 元数据管理:统一管理本体(Schema)、数据字典、血统关系,确保数据的可理解性与一致性。
四、 与展望
大规模知识图谱的存储实战是一个系统工程,它超越了单纯选择一款数据库,而是需要构建一个涵盖数据处理、高效存储、智能查询、稳定运维的全栈支持服务体系。未来的趋势将更加注重存储与计算的分离与融合(如利用云原生存储的弹性,搭配专用图计算引擎)、智能化自治运维(AI4DB)以降低管理复杂度,以及多模态知识图谱的存储与联合查询能力。成功的实践始于对业务需求的深刻理解,并在灵活性、性能与成本之间找到最佳平衡点。