在信息爆炸的今天,企业每天都需要处理TB甚至PB级别的海量数据。传统的数据处理技术在面对如此庞大的数据量时,往往在性能、扩展性和成本上捉襟见肘。此时,以Hadoop为核心的离线批处理技术应运而生,成为了大数据领域不可或缺的基础架构,并催生了完善的数据处理与存储支持服务生态。
一、海量数据处理的核心挑战与离线批处理
海量数据处理并非单纯地“放大”传统流程,它面临着三大核心挑战:数据规模巨大、计算复杂度高、硬件故障成为常态。离线批处理技术正是为应对这些挑战而设计。其核心理念是“分而治之”:将庞大的数据集分割成多个小块(分片),分发到大规模廉价服务器集群中进行并行计算,最后汇果。这种模式不要求实时响应,允许在数分钟到数小时甚至更长时间内完成计算任务,非常适合用于日志分析、数据仓库ETL、历史数据挖掘、报表生成等场景。
二、Hadoop:离线批处理的技术基石
Hadoop是一个开源的分布式系统基础架构,它完美地实现了离线批处理的理念,主要由两大核心组件构成:
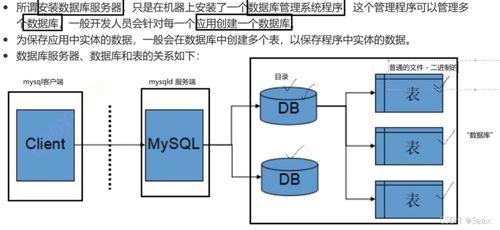
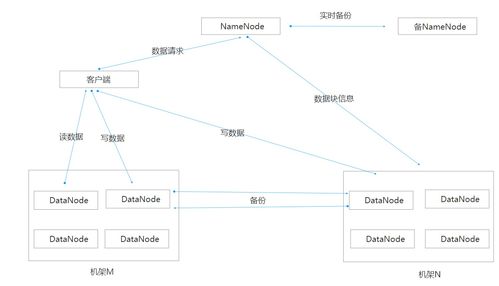
- HDFS(Hadoop Distributed File System):分布式文件系统。它是海量数据存储的基石。HDFS将文件分割成固定大小的数据块(默认为128MB),并以多副本(默认为3份)的形式分散存储在集群的各个节点上。这种设计提供了极高的容错性(个别节点宕机不影响数据可用性)和吞吐量(支持数据并行读写),满足了海量数据存储的需求。
- MapReduce:分布式计算框架。它是海量数据计算的引擎。其计算模型分为两个阶段:
- Map(映射)阶段:将输入数据分片,由多个Map任务并行处理,输出一系列中间键值对。
- Reduce(归约)阶段:将Map阶段输出的、拥有相同键的中间结果进行汇总、计算,生成最终结果。
这种简单的模型屏蔽了底层复杂的分布式编程细节(如任务调度、节点通信、容错处理),使开发者能够专注于业务逻辑本身。
三、围绕Hadoop的数据处理与存储支持服务
单纯的Hadoop核心组件如同汽车的引擎和底盘,要使其高效、稳定、易用地运行,还需要一整套支持服务。这些服务构成了现代大数据平台的关键部分:
1. 资源管理与调度服务
- YARN(Yet Another Resource Negotiator):Hadoop 2.0引入的核心组件,它将资源管理与作业调度/监控功能分离。YARN作为一个集群资源管理器,负责统一管理集群的计算资源(CPU、内存),并为上层各种计算框架(如MapReduce、Spark、Flink)提供资源调度服务,使Hadoop从单一的批处理系统演进为一个多任务、多租户的数据操作系统。
2. 数据集成与处理服务
- Apache Hive:基于Hadoop的数据仓库工具,它提供了类似SQL的查询语言(HQL),可以将结构化的数据文件映射为一张数据库表,并将SQL语句自动转换为MapReduce或Tez/Spark任务执行,极大降低了数据开发人员的学习和使用门槛。
- Apache Pig:提供了一种高级脚本语言(Pig Latin),用于描述数据流处理过程,同样会编译成MapReduce任务执行,适合进行复杂的数据流水线操作。
- Apache Sqoop:用于在Hadoop与结构化数据库(如MySQL, Oracle)之间高效传输批量数据的工具。
- Apache Flume:一个高可用的、高可靠的分布式日志采集、聚合和传输系统,常用于将海量日志数据从各个服务器实时摄入HDFS。
3. 数据存储优化与管理服务
- Apache HBase:构建在HDFS之上的分布式、面向列的NoSQL数据库。它弥补了HDFS随机读写能力弱的缺点,支持对海量数据的低延迟、随机访问,适用于实时查询场景。
- Apache Parquet / ORC:高效的列式存储格式。与传统的行式存储相比,它们在处理只需要查询部分列的分析型任务时,能极大减少I/O,提升查询性能,并支持更好的压缩。
- Apache ZooKeeper:分布式协调服务,为Hadoop生态中的许多组件(如HBase, Kafka, YARN)提供可靠的分布式锁、配置维护、命名服务等,是保障集群稳定运行的“润滑剂”。
四、与展望
以Hadoop为代表的离线批处理技术,通过分布式存储和计算,从根本上解决了海量数据处理的可行性问题。而围绕其构建的丰富的数据处理与存储支持服务生态,则从易用性、效率、功能完备性等方面将这种能力产品化、服务化,使之成为企业数据中台的坚实底座。尽管如今实时流处理(如Spark Streaming, Flink)和交互式查询(如Impala, Presto)技术发展迅速,但在处理超大规模历史数据、运行复杂ETL作业和生成深度分析报表方面,Hadoop离线批处理技术因其成熟度、稳定性和成本优势,依然占据着不可替代的核心地位。随着云原生、存算分离等理念的深入,Hadoop生态也在不断进化,持续为海量数据的价值挖掘提供强大动力。