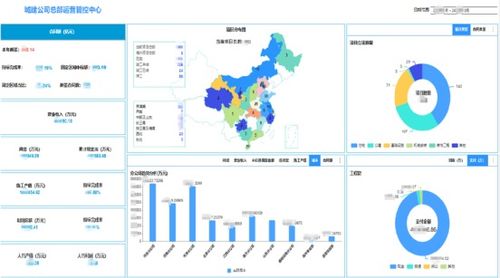
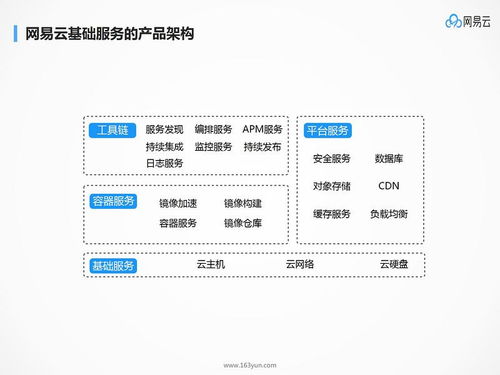
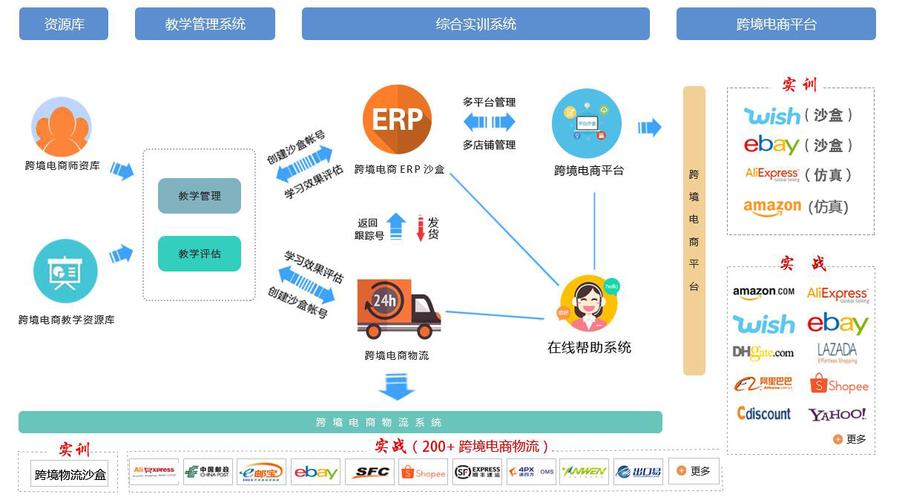
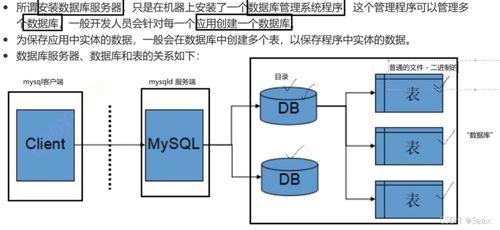
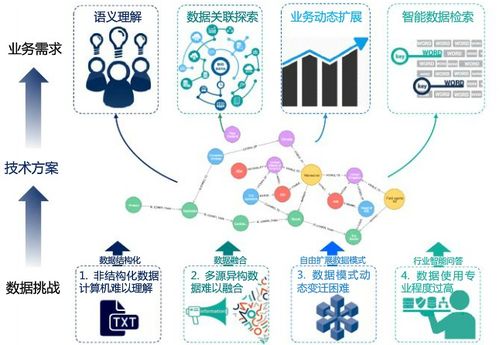
在当今数据驱动的数字时代,高效、可靠的数据处理与存储解决方案是各类应用和业务的命脉。Sewer服务器,并非指向字面意义上的“下水道”,而是作为一个形象化的技术术语或特定产品名称,它代表了一类专门为大规模、高吞吐量的数据流处理与持久化存储提供底层支持的服务平台。其核心价值在于构建一个稳固、可扩展且智能化的“数据管道”基础设施,确保信息能够被顺畅地“收集、传输、净化、加工并最终储存”。
核心功能与角色定位
Sewer服务器的核心角色是充当数据生命周期的“中枢神经系统”和“蓄水池”。其主要功能包括:
- 高吞吐量数据摄入:能够以极低的延迟接收来自各种源头(如物联网设备、应用程序日志、事务系统、传感器网络)的海量、持续流入的数据流,具备强大的并发处理能力。
- 实时流处理与转换:在数据存入长期存储之前或提供实时清洗、过滤、格式化、聚合和丰富化能力。这确保了数据的质量和一致性,为后续分析提供可直接使用的“干净”数据。
- 弹性数据存储与分层:不仅提供高性能的在线存储(如SSD)用于热数据访问,还整合成本优化的归档存储(如对象存储或磁带)用于冷数据。支持结构化、半结构化和非结构化数据的统一存储管理。
- 可靠性与持久性保证:通过数据复制(多副本或纠删码)、备份、快照以及跨地域容灾等机制,确保数据的安全与高可用,满足业务连续性和合规性要求。
- 可扩展性与资源管理:采用分布式架构,能够根据数据量的增长近乎线性地扩展计算和存储资源,并实现资源的动态调度与负载均衡。
技术架构与关键组件
典型的Sewer服务器解决方案通常构建在云原生或分布式系统理念之上,可能涉及以下技术栈:
- 消息队列/流处理平台:如Apache Kafka, Apache Pulsar, Amazon Kinesis,负责高可靠的数据流摄取与缓冲。
- 流处理引擎:如Apache Flink, Apache Spark Streaming,用于实现复杂的实时计算逻辑。
- 分布式存储系统:如HDFS, Ceph,或云服务提供的对象存储(如AWS S3)、块存储、文件存储服务。
- 数据编排与调度:如Apache Airflow,用于管理复杂的数据管道工作流。
- 元数据管理与目录服务:跟踪数据来源、血统、模式和访问权限。
应用场景与价值
Sewer服务器是支撑以下场景的隐形英雄:
- 大数据分析与商业智能(BI):为数据仓库和数据湖持续输送高质量的原料数据。
- 实时监控与告警:处理IT运维、金融交易、工业物联网中的实时指标流,实现即时洞察。
- 事件驱动型应用:支撑微服务架构中的异步通信和数据同步。
- 机器学习和人工智能:为模型训练和推理提供持续、稳定的数据流水线。
****
总而言之,Sewer服务器是现代数据基础设施中至关重要的一环。它超越了简单的存储硬件概念,是一个集数据接入、处理、治理和存储于一体的综合性支持服务平台。通过构建这样一个健壮的“数据排污与处理系统”,企业能够确保其宝贵的数据资产得到高效、安全的管理,从而释放数据的最大价值,驱动智能决策与业务创新。在数据洪流汹涌的今天,一个设计良好的Sewer服务器是任何希望构建数据驱动型组织的技术基石。