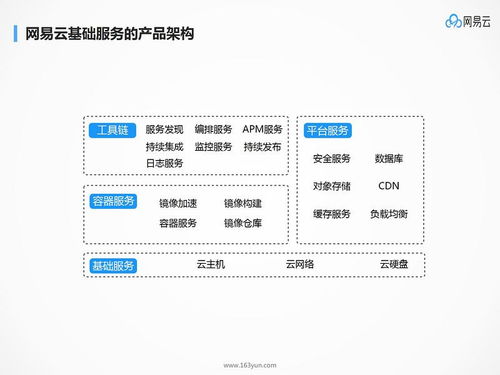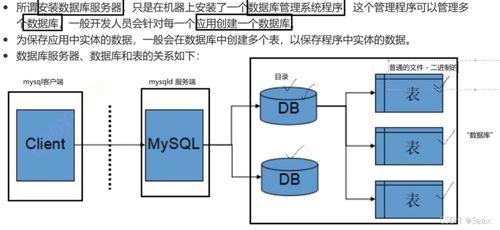
随着大数据时代的到来,企业核心业务系统往往因处理海量数据而变得臃肿低效,影响整体响应速度和扩展性。因此,为业务“瘦身”已成为企业数字化转型的必然选择。本文将手把手带你搭建一套高效的海量数据实时处理架构,结合数据处理和存储支持服务,助力企业释放数据潜力,提升业务敏捷性。
一、海量数据处理的挑战与“瘦身”必要性
核心业务系统在数据量激增的背景下,常面临以下痛点:
- 数据处理延迟高:传统批处理方式无法满足实时业务需求,导致决策滞后。
- 存储成本飙升:非结构化数据(如日志、图像)占用大量空间,且查询效率低下。
- 系统扩展性差:单点架构难以应对突发流量,容易导致服务中断。
“瘦身”并非单纯削减功能,而是通过优化数据处理流程,将非核心任务剥离,聚焦高价值业务逻辑。这不仅能降低系统负载,还能提升用户体验和运营效率。
二、搭建实时处理架构的关键步骤
一个强大的海量数据实时处理架构通常包括数据采集、处理、存储和分析四个环节。以下是逐步搭建指南:
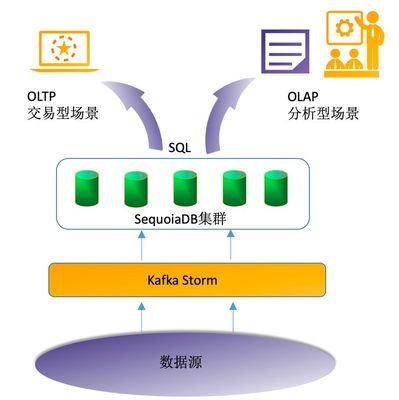
- 数据采集层:采用分布式消息队列(如Kafka或Pulsar)作为入口,支持高吞吐量的数据流入。例如,部署Kafka集群,配置多个主题(Topics)以分类处理业务数据,确保数据不丢失且低延迟。
- 数据处理层:引入流处理引擎(如Apache Flink或Spark Streaming)进行实时计算。通过编写处理逻辑(如过滤、聚合、转换),实现对数据的即时分析。例如,使用Flink处理用户行为流,实时识别异常模式并触发告警。
- 数据存储层:选择混合存储方案,结合NoSQL数据库(如Cassandra或HBase)用于高速读写,以及数据湖(如AWS S3或HDFS)存储原始数据。这支持灵活查询和历史回溯,同时控制成本。
- 数据服务层:通过API网关和微服务架构,暴露处理后的数据给业务系统。例如,构建RESTful API,让前端应用实时获取分析结果。
整个架构需辅以监控工具(如Prometheus)和自动化运维,确保高可用和可扩展性。
三、数据处理和存储支持服务的集成
为简化搭建过程,企业可借助云端数据处理服务(如AWS Kinesis或Google Dataflow)和存储服务(如云对象存储或分布式数据库)。这些服务提供托管解决方案,减少运维负担:
- 数据处理服务:自动扩展计算资源,处理峰值流量;例如,使用Kinesis Data Streams实时处理点击流数据。
- 存储支持服务:提供分层存储选项,冷数据归档至低成本存储,热数据存于内存数据库(如Redis)以加速访问。
通过集成这些服务,企业只需关注业务逻辑,快速实现“瘦身”目标。
四、实践案例与最佳实践
以电商行业为例:某平台通过搭建上述架构,将订单处理从批处理改为实时流处理,延迟从小时级降至秒级,同时利用云存储服务降低了30%的存储成本。关键最佳实践包括:
- 逐步迁移:先从小规模数据流开始测试,再扩展至核心业务。
- 数据治理:实施数据清洗和标准化,确保质量。
- 安全合规:加密数据传输和存储,遵循GDPR等法规。
五、总结与展望
核心业务“瘦身”不仅是技术优化,更是战略转型。通过手把手搭建海量数据实时处理架构,并整合数据处理和存储支持服务,企业能构建敏捷、高效的数据驱动体系。随着AI和边缘计算的融合,实时处理将更智能,助力企业在竞争中脱颖而出。开始行动吧,让你的业务轻装上阵,驾驭数据洪流!